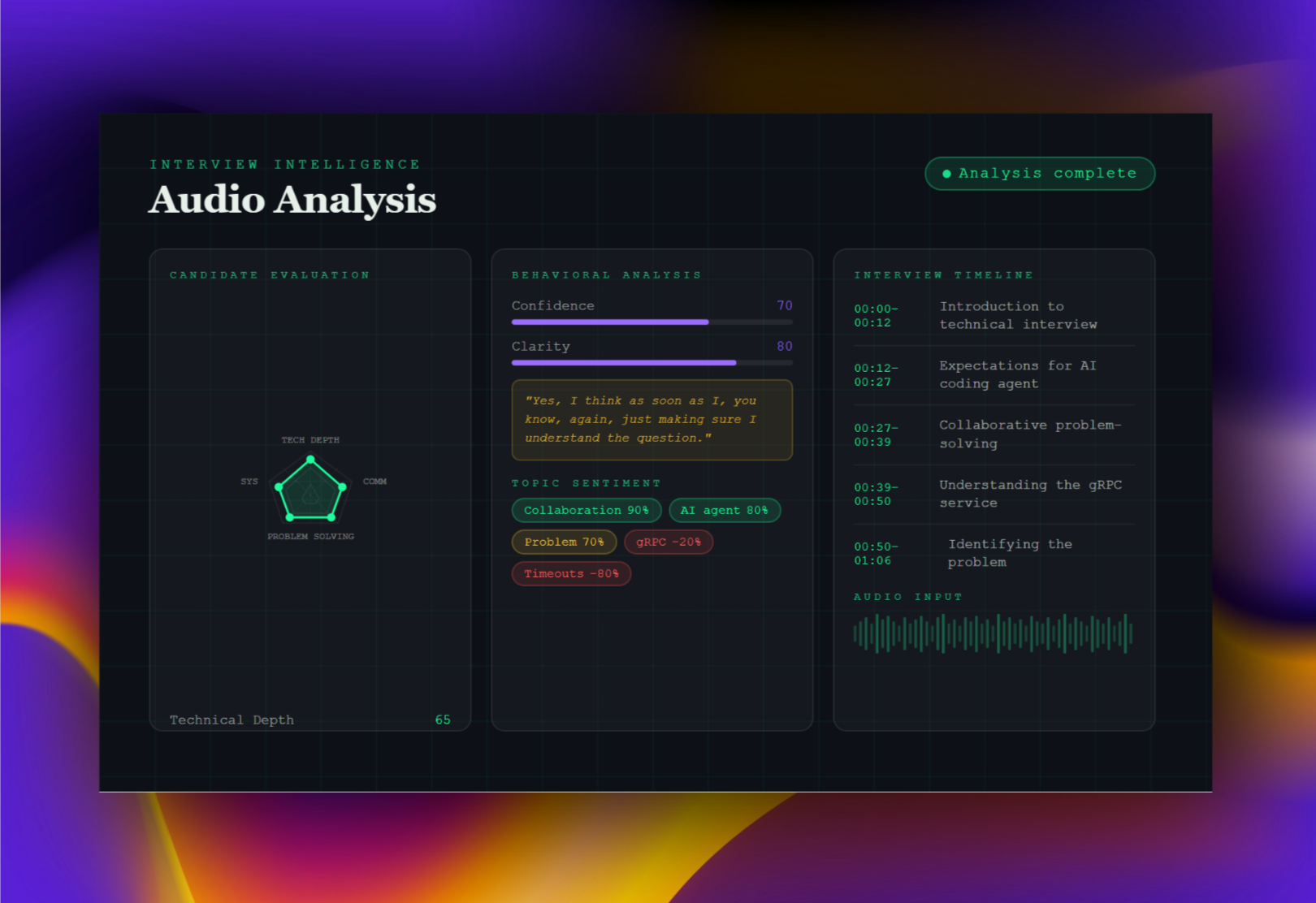
Interview Intelligence: AI Audio Analyst
Drop in an interview recording, get a full candidate report in seconds. Produces multi-dimensional scoring across technical depth, communication clarity, and problem solving — with radar charts, behavioral hesitation signals, topic sentiment, and a timestamped interview timeline. Built on a RAG pipeline with FastAPI and React.
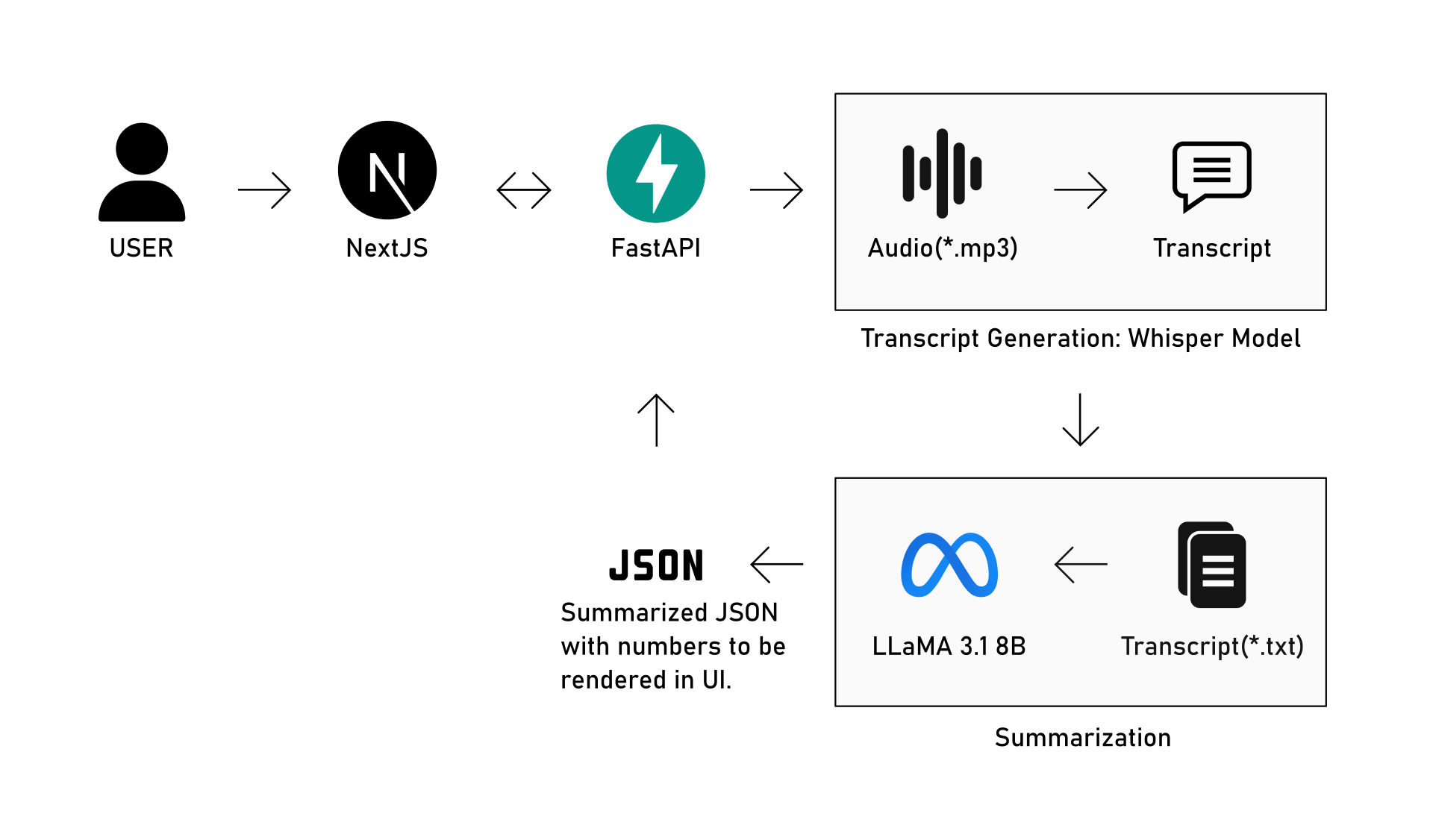
The pipeline takes a raw interview audio file and transforms it into a structured JSON report through two sequential AI stages, all orchestrated by a FastAPI backend sitting between the user and the processing layers.